PromptQL Design
PromptQL is a novel agent approach to enable high-trust LLM interaction with business data & systems.
Unlike traditional tool calling & RAG approaches that rely on in-context composition, PromptQL's planning engine generates and runs programs that compose tool calls and LLM tasks in a way that provides a high degree of explainability, accuracy and repeatability, for arbitrarily complex tasks.
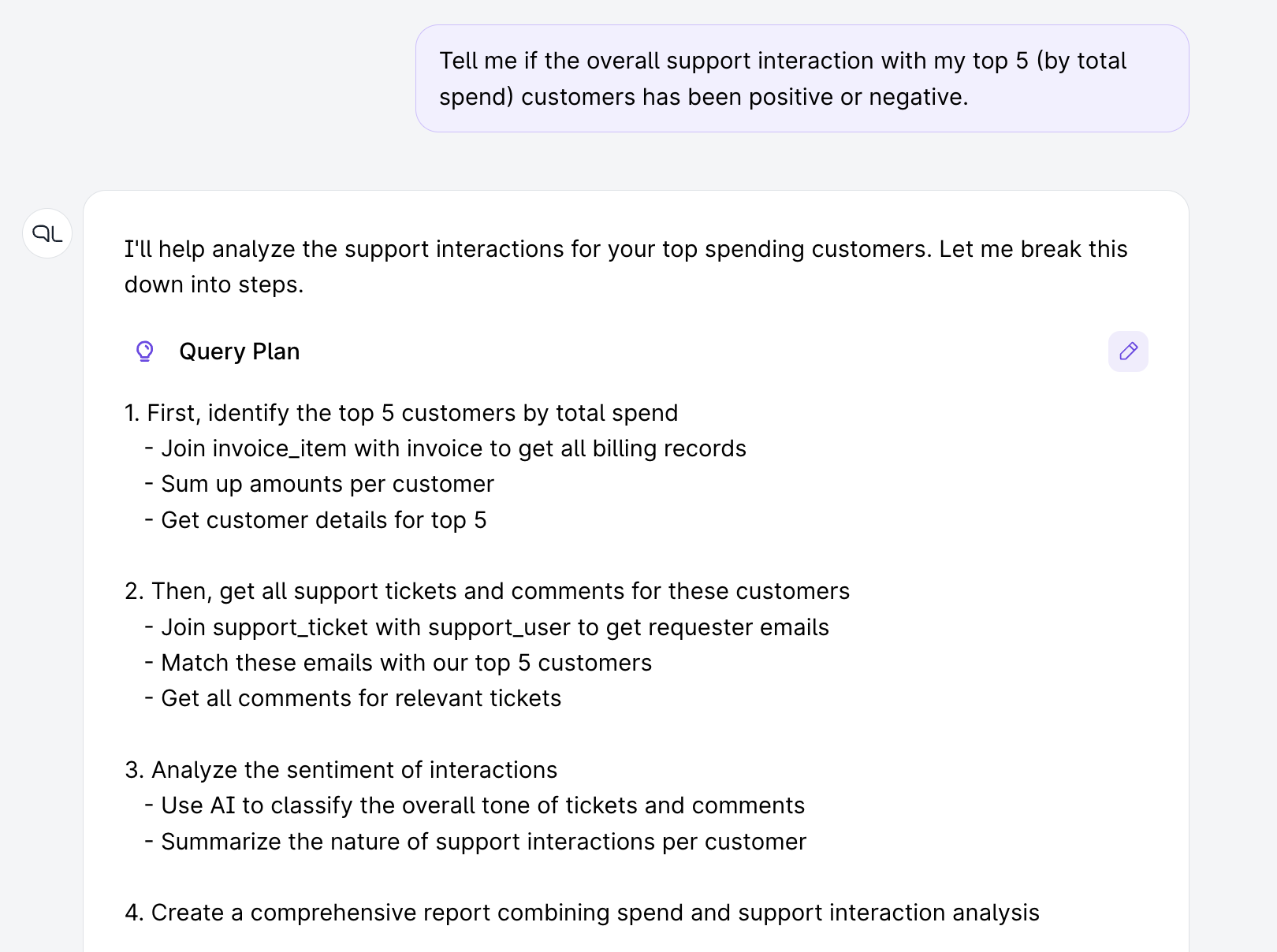
A PromptQL agent creating a query plan for a complex task, interleaving operations on structured/unstructred data.
PromptQL precisely composes retrieval, compuatutational & LLM tasks with explainable and steerable query plans.
Compared to tool calling
~2x improvement in accuracy.
Near-perfect repeatability as complexity of task & size of working set increases.
Constant context size as data in working set increases.
Lower token consumption for complex tasks.
| Evaluation | PromptQL | Tool calling (Claude + MCP) | Comment |
|---|---|---|---|
|
Task: Help the user get the top 5 priority tickets, taking into account the criticality of the ticket, the associated project plan tier, the project revenue and so on. Legend: Colors represent accuracy. Columns represent 5 runs of the same prompt. | Task over 5 tickets: Highest priority ticket is correct. | ||
| Task over 10 tickets: None of the high priority tickets are in the right order. | |||
| Task over 20 tickets: ~50% of the high priority tickets are missing. |
| Evaluation | PromptQL |
|---|---|
|
Task: Help the user get the top 5 priority tickets, taking into account the criticality of the ticket, the associated project plan tier, the project revenue and so on. Legend: Colors represent accuracy. Columns represent 5 runs of the same prompt. | |
| Comment | Tool calling |
|---|---|
| Task over 5 tickets: Highest priority ticket is correct. | |
| Task over 10 tickets: None of the high priority tickets are in the right order. | |
| Task over 20 tickets: ~50% of the high priority tickets are missing. |
Challenges with in-context tool chaining
Challenge #1: Accuracy & repeatability deteriorate as the instruction complexity increases and/or the amount of data in-context increases.

Ignores rule that advanced plan > free plan in priority.
Challenge #2: In-context approaches risk running into hard LLM limitations around input and output token limits. For example, if retrieved data from a data tool call needs to be passed to a code execution tool, the entire data has to be printed as a variable into the source code of the program. Or, the response of a data retrieval tool call might result in crossing the size of the context window.
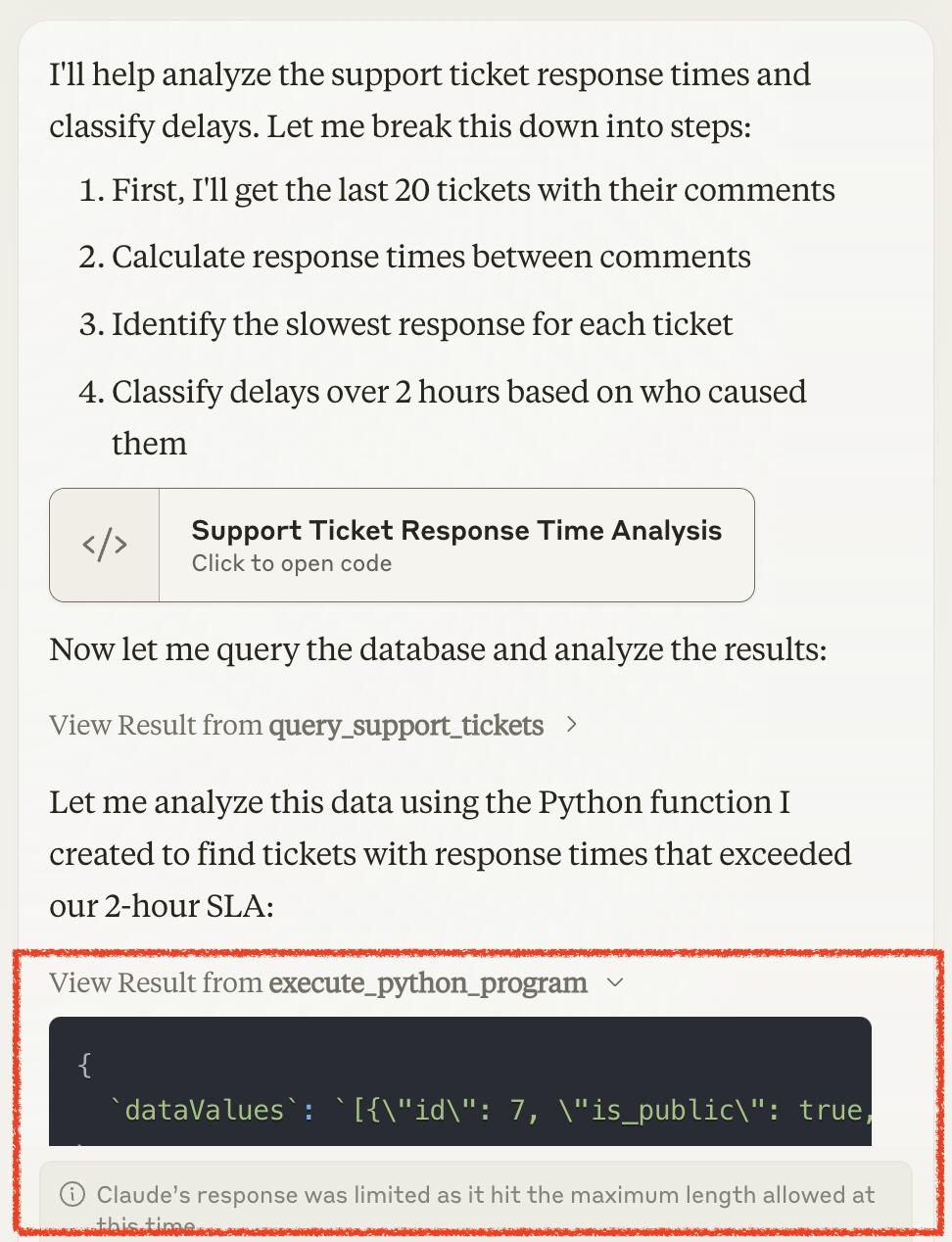
Passing data between tools in context runs against the output token limit
Introducing PromptQL
PromptQL's goal is to ensure that AI connected to data and systems can realistically be introduced into business operations & workflows. This requires a high degree of accuracy and repeatability.
To do this, PromptQL separates the creation of a query plan that describes the interaction with the business data, from the execution of the query plan.
PromptQL uses the LLM to first create a program to compose the different tool calls. PromptQL has programmatic primitives for LLM tasks. This allows retrieval, computational and "cognitive" tasks to be arbitrarily composed.
Once the program is created, it is executed in code.
This approach has a few important implications:
- It removes input and output data generated during the execution of the plan from the current context.
- Programmatic execution of the desired plan makes it deterministic and repeatable.
- It allows the user to steer the generation of the plan.
There are 3 key components of PromptQL:
- PromptQL programs are Python programs that read & write data via python functions. PromptQL programs are generated by LLMs.
- PromptQL primitives are LLM primitives that are available as python functions in the PromptQL program to perform common "AI" tasks on data.
- PromptQL artifacts are stores of data and can be referenced from PromptQL programs. PromptQL programs can create artifacts.
A PromptQL agent creates and runs PromptQL programs.
PromptQL programs
A PromptQL program is a concrete representation of the user's intended interaction with the business data.
PromptQL program that fetches the last 10 unread emails
# Fetch last 10 unread emailsemails = fetch_emails(limit=10, unread=True)# Calculate averageaverage = sum(emails) / len(emails)
PromptQL programs can read/write data, or search through data by invoking Python functions. These tools are implemented outside of PromptQL, and should simply be provided as dependencies to the PromptQL program. Here are some typical examples of tools:
- Search (vector, attribute, keyword, etc)
- Reading and writing data from a database
- Interacting with an API
The most important factor that determines the effectiveness of PromptQL are:
- The quality of the tools provided to PromptQL
- The ability of the PromptQL agent to consistently generate high quality PromptQL programs
PromptQL primitives
PromptQL primitives are AI functions that are available as python functions in the PromptQL program to perform common AI tasks on data. These primitives can create structured information from unstructured and structured data and allow the composition of "cognitive" tasks with "computational" tasks.
For example, a simple search based RAG system can be represented as a PromptQL program with a retrieval function followed by a PromptQL primitive that then generates the result.
These are the 3 basic PromptQL primitives:
- classify
- summarize
- extract
Example PromptQL program with primitives
# A PromptQL program that uses AI to analyze an emailDate: Thu, 14 Mar 2024 15:23:47 +0000Subject: URGENT: Your Assistance Required - $25M InheritanceDear Beloved Friend,I am Prince Mohammed Ibrahim, the son of late King Ibrahim of Nigeria. I am writing to request your urgent assistance in transferring the sum of $25,000,000 (Twenty-Five Million United States Dollars) from my father's account to your account.As the sole heir to the throne and my father's fortune, I need a trusted foreign partner to help move these funds out of the country due to political instability. In return for your assistance, I am prepared to offer you 25% of the total sum.To proceed, I only require:1. Your full name2. Bank account details3. A small processing fee of $1,000Please treat this matter with utmost confidentiality and respond urgently.Best regards,Prince Mohammed IbrahimRoyal Family of NigeriaTel: +234 801 234 5678"""# Extract the sender's email using the extract primitivejson_schema = {"type": "object","properties": {"sender_email": {"type": "string","description": "The email address of the sender"}}}extracted_info = primitives_extract(json_schema=json_schema,instructions="Extract the sender's email address from the email header (From: field)",input=email_text)# Classify if it's spamclassification = primitives_classify(instructions="Determine if this email is likely to be spam/scam based on its content, tone, and characteristics",inputs_to_classify=[email_text],categories=['Likely Spam', 'Legitimate Email'],allow_multiple=False)# Store results in an artifactresult = [{'email_content': email_text,'extracted_sender': extracted_info.get('sender_email'),'spam_classification': classification[0]}]print(result)
PromptQL artifacts
PromptQL artifacts are stores of data and can be referenced from PromptQL programs. PromptQL programs can create artifacts. These are the 2 necessary artifacts for PromptQL:
- Text artifacts
- Table artifacts
Example PromptQL program that fetches the last 10 unread emails and stores them in an artifact
# Fetch last 10 unread emailsemails = fetch_emails(limit=10, unread=True)# Create a list with one dictionary containing the emailsresult = []for email in emails:result.append({'email': email})# Store as an artifactstore_table_artifact('emails','Last 10 unread emails','table',result)
PromptQL programs can load previously generated artifacts, and this creates a form of structured memory for PromptQL programs, allowing them to surpass limitations introduced by passing data in context.
Example PromptQL program with artifacts
# Create a function to extract the sender's email address from an emaildef get_sender_email(email):extracted_info = primitives_extract(json_schema=json_schema,instructions="Extract the sender's email address from the email header (From: field)",input=email)return extracted_info.get('sender_email')# Create a function to classify an email as spam/scamdef classify_email(email):classification = primitives_classify(instructions="Determine if this email is likely to be spam/scam based on its content, tone, and characteristics",inputs_to_classify=[email],categories=['Likely Spam', 'Legitimate Email'],allow_multiple=False)return classification[0]emails = get_table_artifact('emails')# For each email, extract the sender's email address and classify if it's spamresult = []for email in emails:result.append({'email': email,'sender_email': get_sender_email(email),'spam_classification': classify_email(email)})# Run an action to mark the email as spamfor email in result:if email['spam_classification'] == 'Likely Spam':mark_email_as_spam(email['email'])



